Attacking those "random" files a couple of days ago provided enough of a challenge to keep me interested for a few hours, especially as it seemed like I was treading new ground in terms of spec'ing out previously unexplored file formats. It turned out that the files had already been mapped and successfully decompressed and the only thing left to do was build an unpacker which was in the pipeline. It seemed my work wasn't exactly fruitless but other, probably smarter people had everything under control. I wasn't about to let that stop me though.
Note (2008-01-11): The full (official?) SDK for this file format has been located which includes both a packer and an unpacker as well as other tools I'm sure are useful for working on the file format. The full name of the file format is "Yaneurao" with the SDK going by the nomenclature of "yaneSDK" which is the stem for the file format signature of "yanepkDx". There is already a .NET version of the SDK so if you're interested in my deconstruction process then read on, otherwise I would recommend using the official/fully-featured SDKs.
The compression format was identified as LZSS and reading through several sites revealed that some of the data I had initially spotted but attributed to SHIFT JIS (or at one point a Unicode Byte Order Marker, perfect for a non-Unicode file) were the tell-tale signatures of LZSS; the gradual degradation into junk data was also typical of the algorithm as the further into the file the stream progresses, the more back references are present.

While I hadn't heard of LZSS, it came as no surprise that it was a modified version of LZ77 which I had come across before though never toyed with. Having to dig through a dense PDF was not my idea of fun and my university days had proven that reading academic proofs rarely lead to workable implementations for me so I searched for a ready-made PHP version which (for reasons which will soon become glaringly apparent) didn't prove fruitful. After coming up against dead-ends with other languages I settled on the defacto C version which seemed most other versions I found were based off.
Ignoring my original deconstruction script for the moment, I worked on the assumption that each individual file contained within the large .dat files were individually compressed given that each file had a readable opening section of bytes and (according to the LZSS spec) didn't have any back references. Like with other implementations of algorithms I didn't fully understand, I copied the C code more or less exactly, altering formatting to my tastes and altering code to take into account any PHP idioms that I could foresee. Checking things over, I pumped in one of the compressed files and, unsurprisingly, the output file was more or less blank. After rechecking the code and running it again, the output file was once again filled with spaces and some sporadic junk bytes that didn't look familiar.
The script wasn't even outputting the uncompressed data at the beginning of the file and the output was larger than the input but still not the size flagged in the original .dat files. After scratching my head for a while I set about spitting out some debug data to pinpoint what had gone wrong and where. The algorithm is broken down into roughly three main sections, in two main control structures. Putting in some basic output formatting to check each section was executing proved that each section was being run in a way that I could only assume was correct:

This assumption of course turned out to be false but I wouldn't realise this until later in the day. The LZSS algorithm uses a number of constants to define things such as the size of the sliding buffer window, maximal reference length and minimal reference length (a change from the LZ77 algorithm to prevent the encoding being longer than the original) so I tweaked the values first with sensible then ridiculous values only to have the script spit out similarly broken output. The C algorithm also had several places where it used hex values to do bitwise operations, converting these to decimal (obviously) proved ineffective and I was ready by now to admit that I was stumped. I had been working on it for a while now so I took a break for lunch, during which I decided to ditch the C algorithm and start from scratch so that I actually understood what was going on.
This proved even more torturous so I switched back to my original script and started spitting out some fairly detailed output including: the section of the algorithm, the current byte location in the stream, the hex value of the most pertinent read byte and the binary value of that byte.
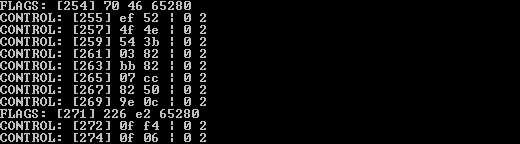
This more or less nailed down that the entire implementation was broken, the values it was generating from the very beginning were incorrect which of course meant all the back references and so forth were incorrect. Using the binary output and a bit of paper I worked out what the values were supposed to be and started following the values through the algorithm. This part was absolutely essential to working out what was wrong with the implementation of the algorithm as it elucidated what each part did:
- The first section (which I had termed "FLAGS") worked out whether a byte was a control byte and set a flags variable
- The second section (which I had termed "AND1") assumed it was reading a raw byte and simply wrote it to the output stream (and the buffer).
- The third section (which I had termed "CONTROL") read the two control bytes which formed a back reference and then read the appropriate data from the buffer and subsequently the output.
From my output it was apparent the meat of the algorithm, reading the raw data, wasn't being done. Then, in that moment of lucid elation, I realised exactly what was going wrong.
PHP was grabbing a byte from the input file as a string, and being a loosely-typed language meant that when it came to doing bitwise operations, the underlying type was incredibly important. I'm more than willing to admit that this state of affairs was my own damn fault for prototyping this in a language that wasn't built for algorithms and bit level operations and had I done this in a strongly-typed language, everything would have been dandy. Of course, had I simply dumped the implementation I found into a C file and compiled away, I wouldn't really understand what was going on, so my retardedness didn't go to waste.
Long story short, forcing the read bytes into an integer using the ord() function (and intval() just to make sure) solved the issue and the file I was working on transformed before my eyes.
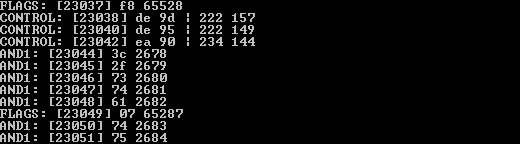

Almost.
Turns out what "sage" had said in my comments on the original version of my unpacker was slightly wrong, the sliding window wasn't 256 bytes (0x100) but the standard LZSS implementation window size of 4096 bytes which means that nothing really needed to be changed from the standard C implementation of the algorithm. As a proof of concept:
Sample LZSS compressed file, Sample uncompressed file
So I now present version 1.1 of the deconstructor script which is released under the same Creative Commons Attribution 2.0 Generic license.
The usage is exactly the same:
php deconstructor.php data1.dat output\
The only difference will be the output spat out by the script which will tell you when a file has been decompressed and whether it succeeded or failed (done by checking the canonical size in the .dat file versus the output size).
To-do
At the moment the script outputs a file to a temporary name and then operates on that file. This isn't optimal but I was having trouble getting my implementation to work in-stream, probably due to fatigue. I may or may not fix that for the PHP version as the next step is to drop the entire deconstructor into a C or C++ file and do a native compile so you don't have to mess around with PHP and I feel like I've developed something in a big-boys' language. If I get the time and the inclination I may do that over the weekend.
As well as the unpacker, I get the feeling that the friend who this is a favour for will require a repacker which will obviously mean doing the LZSS algorithm in reverse and also bundling everything into a .dat file. Should be an intriguing challenge to see if I've learned anything from this little endeavour.