Out of curiosity and a favour to someone, I decided to take a look at some random .dat files that were ripe for the translating; what ensued was a morning of head scratching, hex scrying and using some of the lesser used PHP functions.
Sample File 1, Sample File 2, Sample File 3
All screenshots taken from data1.dat, sample file 1 and the window is resized for the most appropriate screenshot rather than general workability.
First thing I did was to crank open the lovely XVI32 hex editor and have a look at the sample files provided, their .dat extension more or less indicated they were a proprietary format and were unlikely to relinquish their secrets easily. What was known was that the files contained a header portion, a bundle of XML files in a contiguous stream and a lot of junk data. The XML files could be seen and their encoding was stated as SHIFT JIS and, after cursing its existence, I attributed the junk data to that which seemed like a good place to start.

The first eight bytes seemed to be a file signature, but Google searches for all or parts of the signature were fruitless which meant it was time to pick things apart.

The next four bytes were different for each file and at first I thought it was part of the block format that made up the header part of the file but the section repetition for the header block didn't match up so after converting it to a variety of different number formats (I'm no hex wizard and I originally thought it was only a two byte short rather than a four byte integer or long) and assumed it was an unisgned long (32 bits) in Little Endian order.
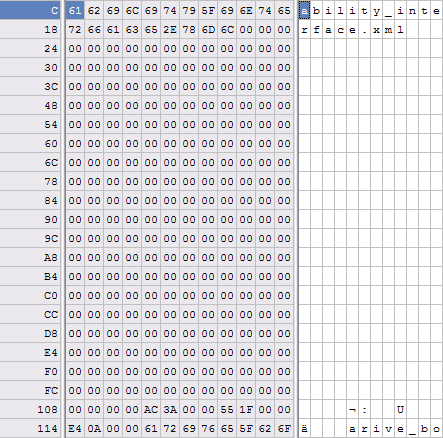
The next section pattern repeated a number of times until the file obviously started with the embedded XML files. After a bit of byte counting and "duh" moments, the general format of the section is:
256 bytes - file path and name
4 bytes - unsigned long
4 bytes - unsigned long
4 bytes - unsigned longAt a total of 268 bytes for each block, this layout repeats for precisely the number of times specified by the very first unsigned long (after the file signature). So the entire header block consists of:
8 bytes - signature "yanepkDx"
4 bytes - number of header entries
(number of header entries * 268 bytes) - header entriesThis was all well and good but didn't really illuminate exactly what the three numbers were. After pulling out all the entries, a few things became clear:
- The first number in each block increases for each successive block
- The second number was always larger than or equal to the third number
- The first number plus the third number always equalled the first number of the block immediately after the current one
So without resorting to rocket science the first number is the absolute byte offset of the filename, the second number was a bit of a mystery, the third number is the length in bytes of the data in the file. After pushing this info through a script it became obvious this was the defacto format of the file, no complex tree structures or other nasties were awaiting; the XML files were pulled out without problem and within a few minutes their original file structure was recreated.
All done right? Wrong. My initial thought that the XML files were SHIFT JIS encoded was indeed correct, however it didn't solve the junk that proliferated some the files.
Sample un-junked file, Sample junked file
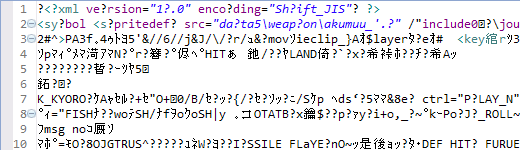
Trying to shift the format into different encodings using known functions only seemed to jumble the junk around rather than get rid of it. It now became apparent that the data was more than likely compressed or otherwise encoded which illuminated what the mysterious second number was in each of the header blocks. The third number represented the packed size of the data, the second represented the unpacked size; this was obvious as the smaller, un-junked files had the same values for each, usually less than 150 bytes.
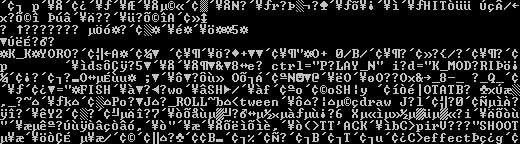
Running both the individual files and the larger .dat file through various decompressors proved less than useful as most of the time the file became so garbled that it sent a few hundred bell tones to my computer speaker making it sound like it was having a seizure. I tried various versions and functions of the gzip/zlib library, bzip2, LHA (of which I knew the Japanese were particularly fond of) and of course good old fashioned zip. It stood to reason that the compression wasn't going to be processor intensive (very few game compression schemes are) which more or less ruled out predictive text algorithms (PPM et al) as well as ACE and 7z formats. The files also seemed to lack any form of dictionary entries as for each file the XML declaration was always in tact which meant that the compression seemed to start an arbitrary length into the file (which would explain why the smaller files were untouched).
This is unfortunately as far as I got after a mornings work and spent a decent amount of time attempting to track down information. The game the files comes from is Battle Moon Wars Act 3 and it seems that they use TYPE MOON characters, other games of which have been successfully translated which may be one avenue to investigate. The developers of the game are "Werk" and if any of their other games (either in the series or otherwise) had been pulled apart, it may give some indication as to where to go forward. There does seem to be information in someone's brain as not only was an "unpacked" version of data1.dat unearthed, but forum posts indicate that work had already begun (if not already aborted) on the technical side of things.
For today at least I'm done with attempting to reverse-engineer arbitrary files and perhaps after sleeping on it some bright idea will be revealed to me that daylight failed to illuminate. For now there is the command line PHP script I quickly prototyped to deconstruct the .dat files (released under the Creative Commons Attribution 2.0 Generic License) and the promise of further work in the future:
Things should be self explanatory from the file; get a command line PHP interpreter set up and run "deconstructor.php" with the name of the file to tear apart and optionally an output folder e.g.
php deconstructor.php data1.dat output\This is an open call for anyone who wants to help with the effort to scry the encoding/compression of the XML files whether you already know or want to take a stab at it, you are more than welcome.